Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。 小刮刮是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者...
”scrapy python代码 爬虫 爬虫程序“ 的搜索结果
python链家数据爬虫,内含源代码和详细的文档说明,欢迎学习。


虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间。Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便。使用Scrapy可以很方便的完成网上数据的采集工作,...

项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行。 最简单的方法:直接使用Timer类 import time import os ...
这个项目有2个爬虫程序和一个网站程序:其中一个爬虫负责分页抓取json格式的数据,分析拿到豆瓣电影的详情页面url地址存入到redis数据库的content_urls集合中;另外一个爬虫负责抓取详情页url的电影内容字段,包括了...
有能人改变了scrapy的队列调度,将起始的网址从start_urls里分离出来,改为从redis读取,多个客户端可以同时读取同一个redis,从而实现了分布式的爬虫。就算在同一台电脑上,也可以多进程的运行爬虫,在大规模抓取的...

微信小程序联盟网站内Demo导入说明: 1:下载小程序开发ide ...安装后图标: 登录,随意一个微信号,扫描后即可登录 ...选择其他组织,在网上搜索一个组织机构代码证 我们就用这个教程里的组织机构 输入个人
内容概要:python scrapy框架,采集豆瓣top100电影详细数据,如标题、评分、时长、主题、简介等,需要其他数据或数据保存方式修改对应方法即可。 适用人群:具有一定python基础,学习应用Scrapy中的朋友。 阅读建议...
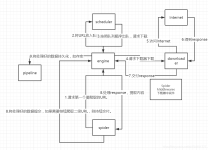
scarpy 不仅提供了 scrapy crawl spider 命令来启动爬虫,还提供了一种利用 API 编写脚本 来启动爬虫的方法。scrapy 基于 twisted 异步网络库构建的,因此需要在 twisted 容器内运行它。可以通过两个 API 运行爬虫:...
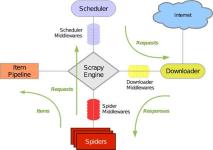
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。
本书从Python的安装开始,详细讲解了Python从简单程序延伸到Python网络爬虫的全过程。本书从实战出发,根据不同的需求选取不同的爬虫,有针对性地讲解了几种Python网络爬虫。本书共8章,涵盖的内容有Python语言的...
1.什么是状态码301301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址...
大家好我是小菜鸡,让我们一起学习Python的网络爬虫框架-Scrapy爬虫框架的使用(一起努力,咱们顶峰相见!!!)
scrapy刚需安装 beautifulsoup刚需安装 mongodb随存储方式安装 反正我这里使用mongo
源代码文件: import scrapy import json from..items import Db250Item class W666Spider(scrapy.Spider): name = 'w666' allowed_domains = ['movie.douban.com'] start_urls = ['...

原标题:Python 爬虫:Scrapy 实例(一)1、创建Scrapy项目似乎所有的框架,开始的第一步都是从创建项目开始的,Scrapy也不例外。在这之前要说明的是Scrapy项目的创建、配置、运行……默认都是在终端下操作的。不要...
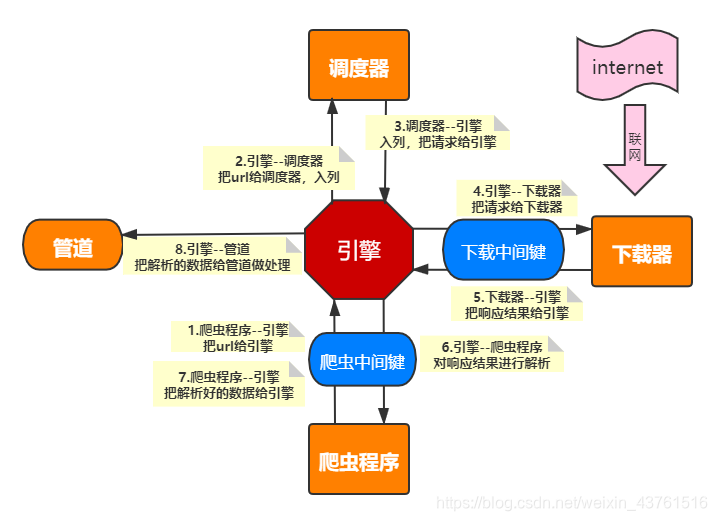
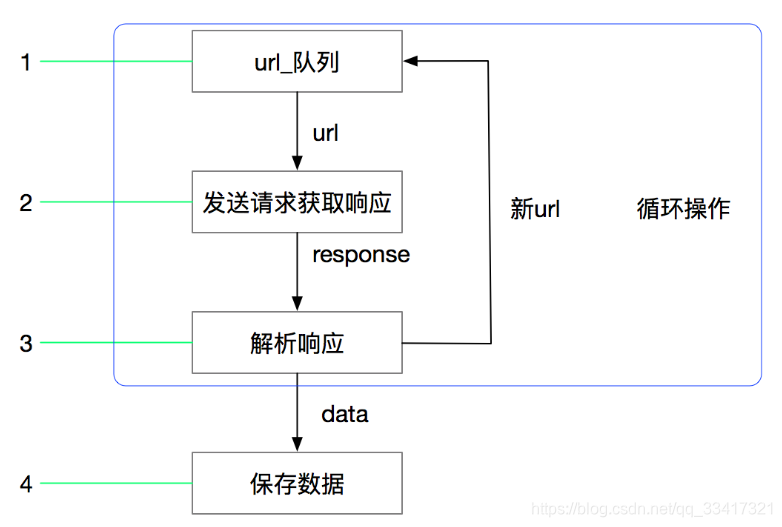
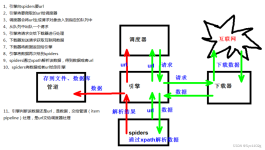
我们通过以上学习,仅编写了2行代码,就完成了爬取数据的工作。
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0,在创建了爬虫程序后,就可以运行爬虫程序了。Scrapy中介绍了几种运行爬虫程序的方式,列举如下:-命令行工具之scrapy runspider(全局命令)-命令行工具之scrapy...
推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地